Talking with Brandon Berry over the weekend, the subject of aging “Hallmarks” came up. I’m not a fan of this terminology, whether it’s applied to aging, cancer or any other biological condition. Surely there’s got to be something more appropriate?
What does “hallmark” mean?
The etymology of “Hallmark” imbues a very specific meaning – uniqueness. In Ye Olden Days, crafts-persons would set up a Guild, a sort-of business association to protect their products and services. The Guild would sometimes be housed in a Guild Hall (an important building in the town, often sharing premises with the town hall or council offices). The Guild Hall would allow members of the Guild to use the Hall Mark – a unique stamp – to mark their wares, so that buyers could be assured of authenticity.
(img from gold.org)
In theory, using a hallmark ALONE made it possible to tell if what you’re looking at is the real deal. Is this a real 24-karat gold ring made by a master jeweler, or a cheap knock-off? The sole purpose of the hallmark is authentication.
Why “hallmark” should not apply to biology
In biology, long ago someone decided that “hallmark” means “common characteristic”, which is a completely different meaning. Now, instead of a hallmark being a unique identifier (like a fingerprint), it’s just a characteristic found a lot of the time (like blond hair). The problem is NONE of the so-called “hallmarks” of aging or cancer are unique to those conditions. They can all be found in other conditions that are not aging or cancer.
Mitochondrial dysfunction? Everywhere! Epigenetic Alterations? All over the place. Altered cell communication? Heard them on Spotify last week. None of these things are unique to aging, and frequently lots of them are found together in situations that are not aging.
Resisting cell death? Hello drugs. Inducing angiogenesis? Meet hypoxia. Evading growth suppression… that’ll be development. Even taking hallmarks into a more specific field such as metabolism doesn’t solve the problem, as many of the phenomena (e.g., the Warburg effect) are found across various other biological states. The problem is with the term hallmarks itself.
So what’s a better term? I’ll concede that the more hallmarks one finds in a given condition, the more likely it is you can label the condition as bona fide aging or cancer. In-fact, one could even say it is ONLY possible to label something as aging or cancer if ALL of the hallmarks are present (and this conveniently ignores that we may not have identified all the hallmarks yet).
Hmm… everything has to be there for it to be complete. You know what that sounds like? HORCRUXES!
For the uninitiated, in the Harry Potter novels, horcruxes are physical objects used to store a person’s soul. The dark wizard Voldemort disperses his soul across 6 horcruxes plus his body, so the only way to kill him is to destroy all 7.
If the definition of aging or cancer ABSOLUTELY requires a complete complement of hallmarks, they’re not hallmarks. They’re horcruxes. To destroy the thing (aging, cancer etc), you have to fix/destroy all the horcruxes.
I would argue that horcruxis a more appropriate term than hallmark when applied to definitions of biological states. It acknowledges that multiple such entities are required to meet the definition of the disease. It allows for a condition in which horcruxes can be present in other settings that are unrelated (e.g. Harry Potter didn’t realize until near the end that he himself was being used as a horcrux by Voldemort). It also acknowledges (as in the case of HP) that part of the problem is just figuring out what the horcruxes are, and we’re a long way off from being able to say we’ve found all of them. My personal opinion is that it sounds better… “stabbing the 7 horcruxes of aging with a basilisk fang!” And finally, it acknowledges a certain degree of magical thinking has to occur, to believe any complex biological process can be distilled into a half dozen simple things.
Coda
I don’t know quite how the decision was made to wholesale change the definition of hallmark from “unique identifier” to “commonly found characteristic”, but my favorite conspiracy theory is the drafters of the original papers were big fans of the Hallmark TV channel 😉
Chaitanya Kulkarni, former post-doc’ in the lab, has moved to industry and is now with Rheos Pharmaceuticals in Boston.
Our former lab tech’ Alyssa Tavino also left in December to go to back to school to be a Physician’s Assistant.
Our long-standing NIH grant (R01-HL071158) received a 1st percentile score at November study section, and we are now in possession of a Notice-of-Award, meaning the lab is funded for the next 4 years. Yay!
So, at the moment the lab is somewhat running on a skeleton staff. We are in need of new post-doctoral fellow (job ad is here) and a new lab’ technician (position is listed here, please search for ref #233866, as the system won’t let me provide a direct link). Both positions are funded by the NIH grant linked above, for those wanting a better idea of the scope of work that the positions will entail.
Right before the Thanksgiving break, while simultaneously attending the SfRBM annual conference (an event featuring lots of hard core wet-bench science grounded in reality), I had the dubious honor of also attending the Longevity Summit. The latter is a new online event featuring talks from leaders in the burgeoning field of longevity research, centered on the new crop of biotechnology firms in this area. For those who want to watch the talks, they’re available here.
Anyone following the aging research field over the past decade or more is probably familiar with the bold claims – human lifespan extension is within our grasp, within some arbitrary time-frame such as 20 years. Famously, such claims have been made by colorful characters such as Aubrey DeGrey (yes, that guy). On the scientific side of things, claims have been repeatedly made for the existence of “longevity genes”, most famously the sirtuins, with Glaxo-Smithkline eventually abandoning their $700m investment in David Sinclair’s company Sirtris once they realized the underlying science was unsound (the exit may have been accelerated by the minor issue of senior personnel selling resveratrol out the back door). I also had fun-and-games uncovering fraud by a senior post-doc’ in the lab of Leonard Guarente, whose lab the sirtuins were discovered in. Throw in a long-standing trend for anti-aging interventions being hawked as dietary supplements, with all manner of polyphenols and other plant-based nutri-ceuticals (resveratrol, quercetin, curcumin, etc.) neatly side-stepping regulation by the FDA, and it’s easy to see how the field of longevity medicine has a reputation for selling “snake oil” based on not very rigorous science. Even such foundational principles as the free radical theory of aging have beenlargelydebunked, and the entire concept that macromolecular damage is an underlying cause of aging has also been criticized. The fact that many aging studies are hugely influenced by survivorship bias is often overlooked, and this leads to an argument that oxidative stress may even be beneficial for aging, because the longest lived organisms have the most of it!
As if the field wasn’t enough of a mess already, things are about to go off the deep end, thanks to the intersection of longevity biotech’ with three other decidedly sketchy things… Artificial Intelligence, Cryptocurrencies, and a Libertarian attitude to regulation…
Before going into detail, I should clarify this blog post is not meant as a complete rip on everyone who came within 100 feet of this event, or the entire field of aging research geroscience. It’s also not meant as an individual critique on any one company, and specifically is not a direct critique of the company named “Longevity Biotech“, or any specific technology or scientist. Rather, it is a lament about the entire ecosystem of longevity biotech, and how it appears to be a bit “flaky”.
For sure there were a few good talks at the Longevity Summit, and most notably the opening lecture from Charles Brenner had a great take-down on all of the reasons why longevity genes are unlikely to exist (TL/DR – genes only propagate if selected for, and there’s no selective pressure for longevity after reproductive age). There was also a thought-provoking talk from Antonio Tataranni of PepsiCo, about the role the food and beverage industry has to play in making lifespan-extending interventions (if such things exist) more accessible by putting them in food. This idea has some historical precedent (iodine in table salt, vitamin D in milk, fortified breakfast cereals etc.), but would have sounded better coming from a representative of the USDA, rather than someone working for the second largest food & beverage corporation on the planet, which is partly responsible for our current obesity epidemic.
So, there was some good stuff, but the inflection point for me came with the realization that are an absolute shit-ton of new biotech’ start-ups in the longevity field, and as of today (Dec’ 2021) not a single one of them has bought a drug to market! We’re talking billions of dollars of investment, largely based on hype, and so far it’s all just pre-clinical testing or Phase I trials at the very most, with a lot of dietary supplements and other FDA end-runs mixed in. Put simply, despite the bold claims, there really isn’t much to show for all that hype and money. Heck, even down in the trenches of basic model-organism research, there simply isn’t a whole lot of consistency or robustness in the data, with simple things such as mouse strain having huge impacts on the effectiveness of anti-aging candidate drugs.
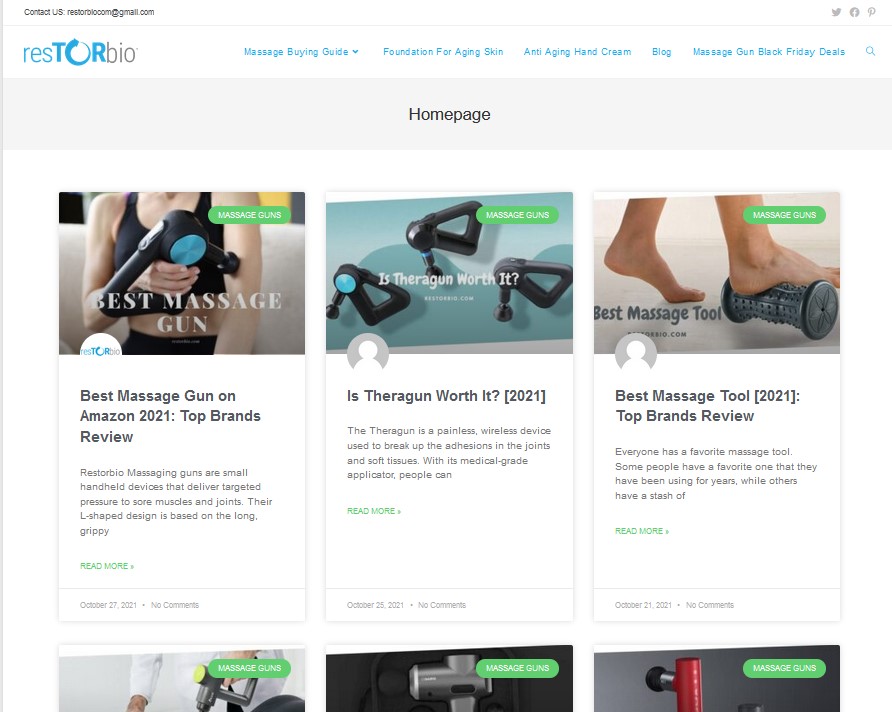
One company in particular, ResTORbio, is targeting mTOR signaling, but appears to have discovered they can make more money selling vibrators personal massagers! (Internet Archive link in-case the site disappears).
Many of these companies are also “meta” (no, not FaceBook but the older meaning of the word). Their intent is not to bring a drug to market. Rather, they’re offering services to the other longevity biotech’ companies who might. As an example, one of the big challenges in the aging field is how to measure aging. Clinical trials cannot simply wait until people die to see if an intervention works, so we need measures of “biological age”. There are some good candidates out there such as the epigenetic methylation clock, or various proteomics based clocks, but the usefulness of these clocks in actual clinical trials is yet to be proven (i.e., there has yet to be a demonstration that altering a human aging clock or biomarker actually equates to extending human lifespan). Some recent data has suggested that such clocks simply do not work, but that hasn’t stopped companies from selling such clocks to the public, to track their “real” age, even though there’s no indication of whether that’s actually a useful number. A potential exit path for many of these clock-based companies is to license their product to a biotech company that actually has a drug candidate, but that company may still have a hard time convincing regulators that measurement X is actually meaningful for human lifespan, rather than just an epiphenomenon. The FDA is pretty rigorous about biomarkers used in trials having a connection to outcomes.
It’s also not surprising that there’s a lot of churn in this area of biotech. Many companies I was planning to list here don’t exist any more, or have been bought out or dissolved. Others simply pivot to a specific disease indication as soon as they get some good data, and abandon aging as an indication. Many of them have websites that make it utterly impossible to figure out exactly what they do, or are designed to give the reader epilepsy. There are a lot of dead links out there in aging biotech, if you read news or blog articles from just a couple of years ago. Many of the companies are focused on very rare diseases, another partial end-run around the FDA by seeking orphan drug designation… get a drug to market for something (anything), then use that foot-hold with off-label prescription to get it into a wider population.
AI/ML
Many of these companies are using machine learning (ML) or artificial intelligence (AI) to do such wonderful things as “analyze millions of data points from every level of biological organization, to create an ever-evolving model that captures the full complexity of aging”. That’s great, but AI has a massive Achilles’ heel known as GIGO – garbage in, garbage out. Put simply, there’s a possibility that most of the data being fed in to these models is of low quality. Many of these AI models rely on -omics data obtained from methods such as RNA-Seq. These methods are very expensive, such that most published RNA-Seq data from academia is usually based on a small number of biological replicates from each experimental group (typically N= 3 or 4). It’s widely acknowledged that much of published academic science is complete crap and not reproducible. The pharmaceutical industry has wasted huge amounts of money failing to reproduce basic findings, and large scale reproducibility studies have been undertaken without very good outcomes. Now take that and dial up the risk with low-N ‘omics data.
There’s a lot of focus in aging research on the Yamanaka factors – four transcription factors that can reprogram cells to pluripotency. Many of the companies are applying “deep learning” to interrogate this, and if you can understand why a model with only 4 variables requires AI or ML to decipher, well I guess good for you. And of course, there are companies using AI/ML to build ever more complex aging clocks which is meta on meta.
Computer modeling in biology can be useful in some areas where the “rules” are well understood, but elsewhere is fraught with problems. For example in metabolic modeling, many of the constants fed into models (kM, Vmax etc) are from decades old literature spread across multiple cell types and tissues. You can’t build a model of the Krebs’ cycle by mixing values from pigeon heart mitochondria and mouse skeletal muscle mitochondria, then test it in HeLa cells. AI-assisted Drug Design does not have a particularly stellar track record, and applications of AI in the life sciences in general are not very reproducible. AI also has huge problems of bias – most famously racism. Train a facial recognition AI model to spot criminals by feeding it pictures of incarcerated persons, who because of systemic racism are overwhelmingly black, and you don’t get a criminal-spotting algorithm, you get a black-spotting algorithm. The American Society of Mathematicians has even gone so far as to call for a boycott on their members working with law enforcement agencies to develop crime prediction tools. As such, I am skeptical that many of the AI models being built in longevity science, based on mice or cell data, will be useful in humans.
Put simply, it is hard to decipher exactly what AI is being used for in longevity biotech, because the usefulness of AI for anything is still a bit of a mystery, so when you apply it to a field with fairly weak foundational science, the problems multiply. Despite AI being a good way to attract money, biology is not digital, so a pure bioinformatics driven approach to “solving” it does not seem deliverable.
Funding
There’s a robust and growing group of venture capital and angel investors willing to fund the “healthy aging revolution”, and just last month a new Longevity Biotech Association was incorporated to promote investment (with many existing Longevity Biotech CEOs on the board). Key players are the Longevity Vision Fund, Apollo Health Ventures, Kizoo, Forever-Healthy, R42 Group, and others. Looking through the websites of these funds reveals hundreds of start-ups, all pulling down tens of millions in funding each, and it’s not hard to estimate this is multi-billion dollar enterprise overall. There are even bizarre longevity biotech online communities, where for the bargain price of $3k a year you can get access to influencers and leading minds in the field (I think I puked a bit in my mouth when I read that site).
A rather scary development in this area is the emergence of cryptocurrency as a source of funding (Bitcoin, Ethereum, Doge, etc). Some of the companies on the list above have come into existence due to the availability of large amounts of money that originated in trading cryptocurrencies. For example, Gordian Biotech has an “Impetus” longevity grant program that is funded by a group of crypto investors. One of the Longevity Summit talks focused on crypto funding for longevity biotech and research. The longevity biotech field also has a lot of overlap with key players in the LifeBoat Foundation, which appears to be a catch-all conspiracy theory website (alien invasions, asteroids, bunkers), with money coming from BitCoin. There are several other strange websites in this area such as Longevity Technology, which seems to be a curated website to bring investors and biotech founders together, with a mix of blog articles and bizarre product placement reviews.
I won’t go into the multitude of problems with Cryptocurrencies, from pump-and-dump schemes to their horrendous carbon footprint. I will simply note that the IRS seems to have taken an interest recently. Once the IRS starts taxing crypto the same way as real money, the bubble will likely contract and many investments may be worthless. I would also hazard a guess that at least some of the companies listed above are actually using some of their seed money to trade crypto as a source of revenue. Hey, if it’s good enough for Tesla then why not? Wouldn’t it be ironic if the people living to 150 years of age were the same ones whose bitcoin investments overheated the very planet they have to spend their extended lifespans on?
Lax Regulation
As evidenced by the final talk of the Longevity Summit, featuring Matt Kaeberlin (the only speaker who doesn’t have a company!) and Elizabeth Parrish (CEO of BioViva), there’s a strong libertarian “government needs to get out of the way” thread running through the longevity industry. While not calling for the outright abolition of the FDA, it was scary that Parrish essentially argued “people are going overseas for these therapeutics, so because of medical tourism we need to fix the regulatory process so they can get those therapies here”. I was impressed that Kaeberlin kept a straight face! Arguing that China (where prisoners are used for clinical trials) or places where governments just don’t care about safety are approving therapies, is not the home run you think it is. Most people are familiar with the reasons why large pharmaceutical companies run trials in poor countries – it’s because they can get away with shit that wouldn’t fly at home (interesting side note – my father worked for a pharma company in Ghana in the 1960s).
We’ve already seen the impact of weakening regulations with the right to try movement, and the disastrous approval of Alzheimers drugs that simply do not work. Some companies are taking an interesting approach – making an end-run around the FDA by trying to get interventions approved for pets such as dogs – with Parrish drawing parallels between the strength of regulations in veterinary and human medicine. As most recently demonstrated by the ivermectin horse-paste debacle, I’m less enthusiastic about dog medicine being the fountain of human youth. As a simple example, the product made by Juvenon is toxic to cats.
The notion that somehow aging is “special” and therefore shouldn’t be regulated like “normal” diseases is not convincing. The same argument could be made about any number of other conditions. For example cancer – for years we’ve been told it’s not one disease but hundreds of diseases, and therefore we need to think about it differently. And yet, cancer medications including personalized therapies such as CAR-T seem perfectly capable of getting approved within the existing framework of the FDA. Reminding people that there’s an entire NIH institute devoted to aging, brings responses such as “the A in NIA just stands for Alzheimers”, which of course immediately overlooks that AD (and Parkinsons and Huntingtons) are all leading causes of age related morbidity.
Overall, it’s just very hard to divorce the whole notion of “aging is different” from “we don’t want to deal with the same laws as other medicine makers”. The case would be a lot more convincing if the medicines actually existed, which they currently don’t. This is known as jumping the gun. If anti-aging therapies would come close to approaching their clinical trial end points, then maybe we would have the basis to discuss an accelerated approval process. Until then, we should not be making special dispensations. We need robust regulation, especially for treatments that people are likely to ingest for several decades of their lives.
Other red flags
(1) Many of the above companies are proposing the use of stem cells. Enough. Said.
(2) A LOT of the science behind the longevity biotech industry is coming from a small number of laboratories concentrated in the San Francisco Bay area, with several biotech founders being affiliated with a few of labs in just a couple of institutions, and these same labs also birthing many of those in the longevity funding VC space. The conflicts of interest created by the blurring of corporate/academic boundaries are troubling. The heads of institutes and the boards of the 100 or so companies, have a lot of overlap. An inordinate number of people in the field are white and young and very good at TeD style presentations.There are a lot of tech-bro’s in this area, with some undoubtedly jacked-up on nootropics. The lack of adequate external oversight created by such an in-bred ecosystem (where the CEOs and lab-scientists and VC funders and influencers and coders are all drawn the same small group of people and often wear multiple hats) again points toward a bubble.
In summary, aging science was already in a bit of a messy state with not a great reputation before biotech’ came along. Now the triple bubble of crypto-currencies, AI-hype and lax regulation, are threatening to make everything a whole lot more sketchy. While extremely expensive and niche options such as plasma therapy (quite literally feasting on the blood of the young) will be available to the ultra-wealthy, personally I don’t believe that – significant human lifespan/healthspan extension with cheap small molecule drugs – will be achieved within a reasonable timeframe, before most of these companies run out of VC money. I remain open to being surprised.
A year and a half into the pandemic, and with the benefit of 20/20 hindsight, I will gladly admit that we fucked up badly by culling our mouse colonies back to a fifth of their normal size in March of 2020 – it’s taken us over a year to get everything back up to size and running again, and meanwhile everyone else just #DGAF and carried along doing mouse work. Ugh!
(1) Our paper with Ana Jimenez of Colgate University, on metabolomics of young and old small and large breed dogs, was finally published in Geroscience. This was part of a larger study by Ana, aimed at addressing the question of why large dogs die prematurely (which is opposite to most of the rest of biology, where large animals live longer). The graphical summary below highlights some key differences in metabolite abundances between fibroblasts from the 4 different groups. Of particular interest (to me) is that carnitine seems to go up as small dogs age, but not large dogs, which might suggest some differences in ability to burn fat, which could be targeted pharmacologically in older dogs.
(3) Our paper on a modified blue-native (BN) gel method was also published, as part of the Methods in Molecular Biology book series. Blue-native is a method for looking at large protein complexes, including so-called “supercomplexes” (SCs) of the mitochondrial respiratory chain. There’s been a lot of debate about the functional importance of SCs, and this paper is the result of a project to streamline the method to reduce a potential artifact source. The project itself was done by an undergrad summer intern, Megan Ngai, who is going to be starting medical school at SUNY upstate next year.
The premise of the modified method is quite simple… most BN methods involve treating your samples somehow, then extracting with detergent, and this step necessarily involves pelleting the mitochondria by centrifugation, prior to extraction. The problem is, doing so might select for “good” or dense mitochondria, and many of the perturbations that have been shown to alter SC formation are also associated with alteration of mito’ density (e.g. respiratory state, PT pore opening). So, what we did was to develop a compromise mito’ buffer that is suitable for both mito’ incubations/treatments and for extraction. This eliminates the pelleting step, so the mito’s that get put on the gel are not “sampled” in any way – they’re representative of the whole population. The upshot is that we find many perturbations of mito’ function simply do not pan out with differences in SC formation or abundance. That’s not to say all the data so far on SC’s is artifactual, but it does suggest that acute alterations in mito’ function really don’t seem to be linked to SCs in a functional manner.
FUNDING
The main R01 that funds the lab (HL-071158) is sadly now in no-cost extension, as the competing renewal application was reviewed in February but missed the payline by 2%. A revision was submitted in July and will be reviewed in October, so we are currently awaiting with fingers crossed. If the news is bad again, it will be the end of the line for this grant which my lab has held since 2003.
Our other funding is in the form of an R56 1 year award (at half modular budget) to gain more data for Aim 2 of the parent R01 application (DK-126659). That award is also in NCE, since the high-fat-diet studies that underpin it were delayed due to the mouse problems outlined above.
So, we’re running on fumes for the time being, hoping for a funding hit and trying to remain productive and optimistic in the interim. This cyclical nature of funding is nothing new, but it bites really hard when a grant you’ve had since your lab began (and which has produced over 100 papers in 17 years) might not make it.
PROJECT HAPPENINGS
We have successfully established a breeding colony of Glo1-/- (glyoxalase-I knockout) mice. The founders came from Jim Galligan in Arizona, and we’re using them to explore methylglyoxal stress in the Alkbh7-/- mice, as reported here.
On a related note, we tried last year to get a “matters arising” published in Nature, regarding a paper on lactylation of lysine residues. A pre-print of our letter is here, in which we point out 3 things. First, the MW of the lactyl-lysine moiety is the same as that of MGO-induced carboxyethyllysine, so mass spec’ alone cannot distinguish these PTMs. Second, the anti-lactyl-lysine antibody developed by the authors (which they sell through the PI’s company) appears to recognize CEL (or another MGO-induced adduct) better than it recognizes lactyl-lysine. Thirdly, the concentrations of lactate used to induce lactylation (25mM) are inhibitory to the enzyme GLO-2, such that they will elevate S-lactoyl-glutathione levels, and this is probably the underlying mechanism driving lactylation (as has been shown by Galligan). Unfortunately, after a year of dicking around Nature decided to reject our letter (and the author’s response) and the authors were quite rude to us about the whole affair, accusing us of stealing their ideas, and telling us to stop confusing people. All highly unprofessional, but par-for-the-course in glam-publishing land. Ugh!
A paper on ERK5 signaling and cardiac mitochondrial hibernation with Jun-Ichi Abe should be out in Redox Biology soon.
Grad student’ Alex Milliken’s project on measuring ROS in intact beating mouse hearts is progressing rapidly. We have built a Langendorff perfusion apparatus into a spectrofluorimeter, which allows measurement of reflectance-fluorescence of the heart, as shown in the picture below:
Using this system we can measure not just parameters like ROS, but also NADH, FADH2, membrane potential (TMRE) and mito’ PT pore opening. While others have done this in larger hearts (guinea pig or rat) this is the first such system in mouse heart, and also the only system with simultaneous measurement of cardiac function at the same time, with a pressure transducer balloon. Thus, we can relate changes in fluorescence to changes in cardiac function in real time.
We’re still working on ALKBH7, trying to figure out its biological function. In that regard, we were intrigued by a recent paper that claims to have discovered a role for the enzyme in regulating mitochondrial ribosomal and RNAs. To us, this is weird, because previously the crystal structure of the enzyme was specifically called out for lacking any binding sites for nucleic acids, as seen in some other ALKBH family members! The authors of the new paper seem to gloss over this by simply stating the enzyme has binding loops conserved from E. coli AlkB. But we’re not convinced the diagrams show any such conservation (rather, just a bunch of disordered structure). Adding to the complication, nothing about this new finding has any impact whatsoever on the underlying phenotype of the Alkbh7 knockout – namely, they don’t die of necrosis! Why would knocking out an RNA demethylase have any impact on acute necrotic signaling? So, this doesn’t really change much about our ongoing quest to determine how the enzyme is involved in necrosis, and how it interfaces with glyoxal metabolism (which the authors conveniently fail to mention, or cite our work). The proteomic data from the paper (which mainly uses siRNA knock down) also disagree with our own findins in knocout mouse hearts – namely they report large scale reductions in mitochondrial transcripts, but we saw no differences in any of the respiratory chain complexes, and no differences in mitochondrial enzyme activities. It could be this is highly cell-type specific, with ALKBH7 having an RNA-processing role in dividing/proliferating cells, versus more of a metabolism/cell-death role in terminally differentiated tissues such as the heart. Lots still to learn about this fascinating protein!
TRAVEL & CONFERENCES
We attended the AHA BVCS conference, where Alex presented a poster. We will also be at the Society for Heart Vascular Metabolism (SHVM) conference in later September, and the Society for Redox Biology & Medicine (SfRBM) conference in November. The latter is supposed to be in person, with Paul presenting at the sunrise free radical school, but I’d say with Covid on the rise, the likelihood of us going to Savannah GA any time soon is not looking high.
3 New papers to add to the lab publications list, to start the year on a good note…
This paper in Chem Med Chem with Paul Tripper’s lab (who are now based in Omaha Nebraska) reports on a new series of diazoxide derivatives, some of which are inhibitors of mitochondrial Complex II.
This paper in Autophagy with Keith Nehrke’s lab reports on the interactions between the hypoxic mitophagy receptor FUNDC1, and the mitochondrial unfolded protein response (mitoUPR) regulator ATFS1.
This paper accepted into JCI Insight (still in press so the link goes to the BioRxiv preprint) with URMC’s Michael O’Reilly and Dave Cohen, reports on the role of fatty acid synthesis in the development of the cardiomyocytes that extend along the pulmonary trunk (yes, the pulmonary vessels have muscle cells and they handle fat just like regular cardiomyocytes do!)